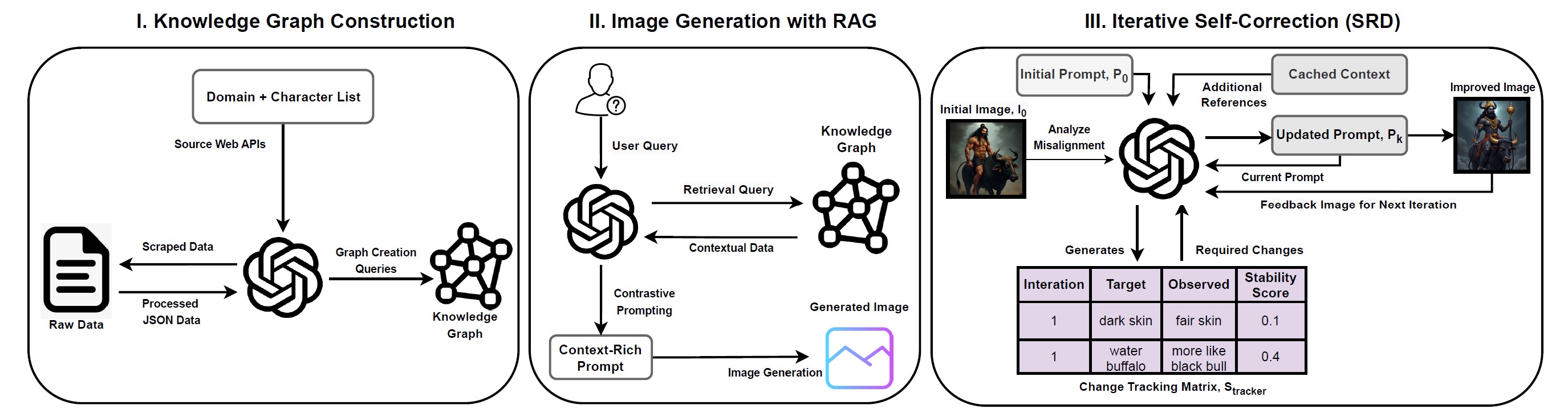
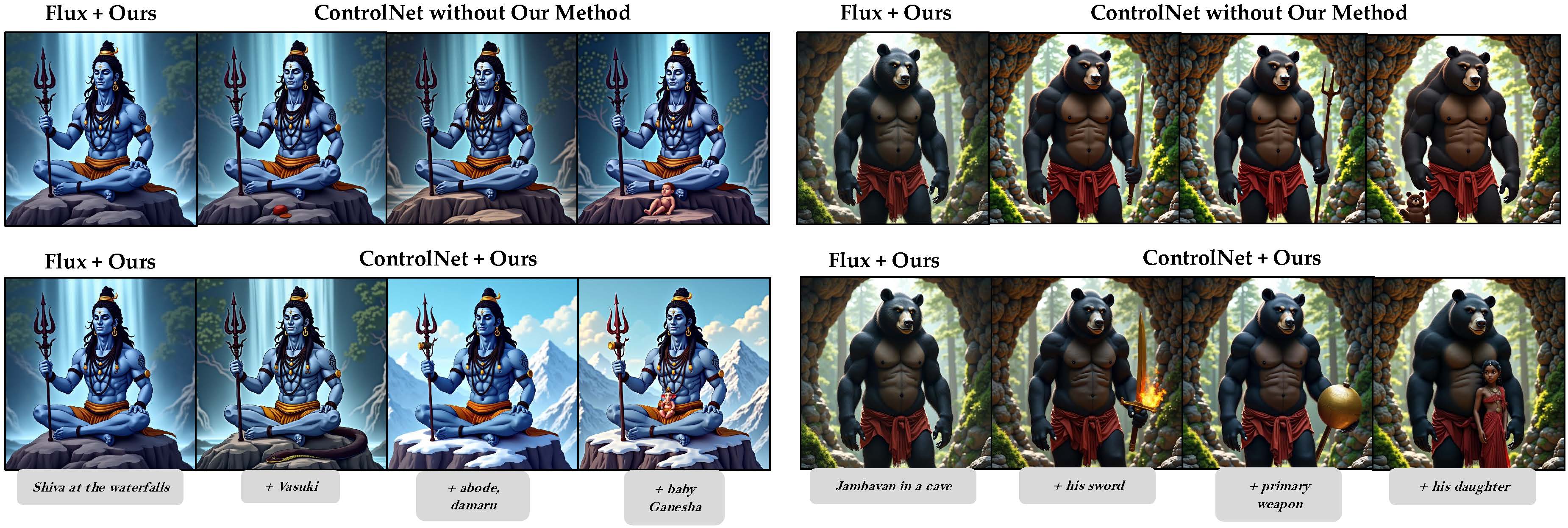
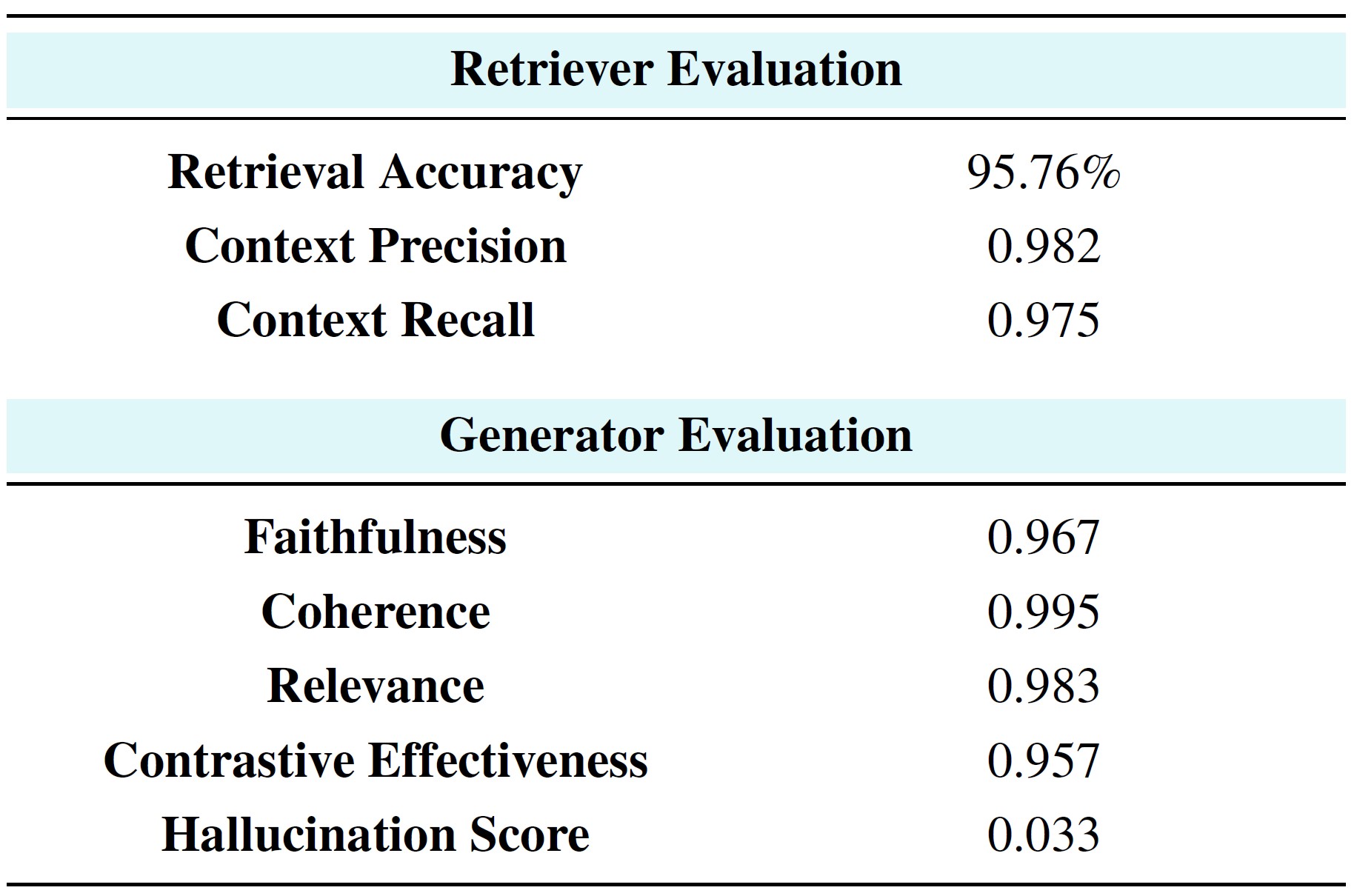
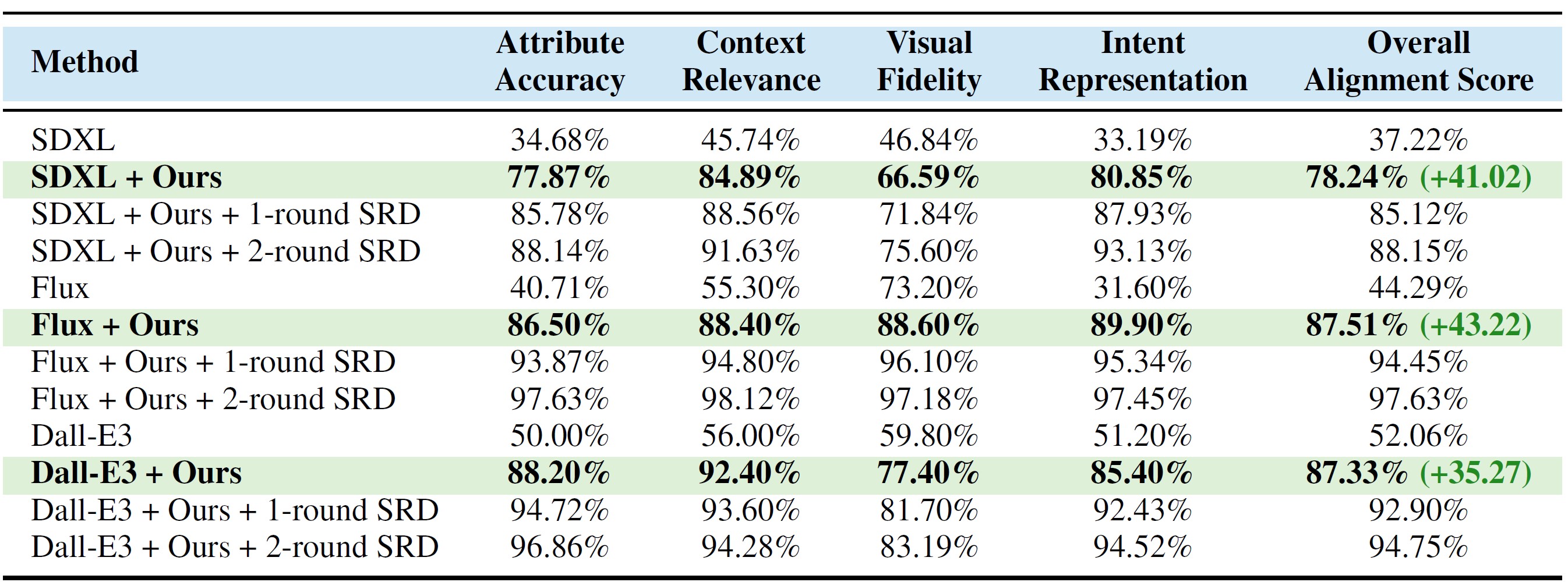
Context Canvas enhances image generation across diverse domains by integrating cultural and contextual details often missed by
standard models. For example, it accurately portrays rare Indian mythological characters like Tumburu with his horse-face and instrument,
and Gandabherunda as a dual-headed bird (top left). Domains such as mythology often comprise characters with multiple forms
(eg.,celestial and human form). Our method picks up subtle cues from user prompts to depict such characters in the right form. For instance,
Indian mythology character, 'Ganga' has a heavenly river form and a human form (Duality), both of which it represents accuratelyIt (left middle).
Our method adapts to various mythologies, capturing Melinoe’s ghostly essence (left bottom) and Zhong Kui’s
fierce warrior form (middle bottom). In Project Gutenberg domains, such as Historical Fiction, Gothic Horror, and Fantasy, it captures
narrative-specific details like Captain Ahab’s ivory leg and gaunt expression (top 4th column) and Edmond Dant`es’ pale skin, coat, and ring
(top 3rd column). For Gothic Horror, it enhances Count Dracula’s menacing presence (middle 3rd column) and infers Manfred’s guilty,
dark persona (middle 4th column). Our approach faithfully represents Lilith with bat wings and snakes
and Lizarel with ethereal beauty and silvery hair (bottom right), demonstrating superior fidelity across cultural and literary domains.